
Classification of Sanskrit Slokas
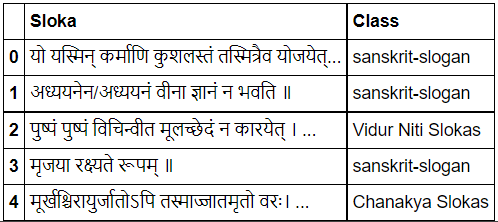
In this project the dataset consisting of Sanskrit slokas were preprocessed to remove unnecessary punctuations and then tokenized data was trained using LSTM to achieve an accuracy of 85% in predicting the author for the sloka.